Blog
Proposal for a Management Architecture for Large Volumes of Data
By Pedro Bonillo, Machine Learning and Big Data Consultant.

By Pedro Bonillo, Machine Learning and Big Data Consultant.
Before describing the components that make up the Big Data Architecture, it is necessary to establish a conceptual framework about them. The four high-level components that make up this Architecture are: (1) Database; (2) Big Data Analytics or BI; (3) Data Science; and, (4) Governance.
Data Warehouses store large volumes of data in defined and static structures that determine the type of analysis that can be done on the data. Therefore, its analytical capacity (reports, dashboards, etc.) is limited by the very structures of the sources.
A Data Lake is a repository of all the data that an organization has or can obtain. The data is "ingested raw" and can be saved "raw", without any predefined schema or structure, or in a structured way. This provides an unlimited window for the use of the data, in such a way that any query, navigation, analysis, etc. can be carried out on it.
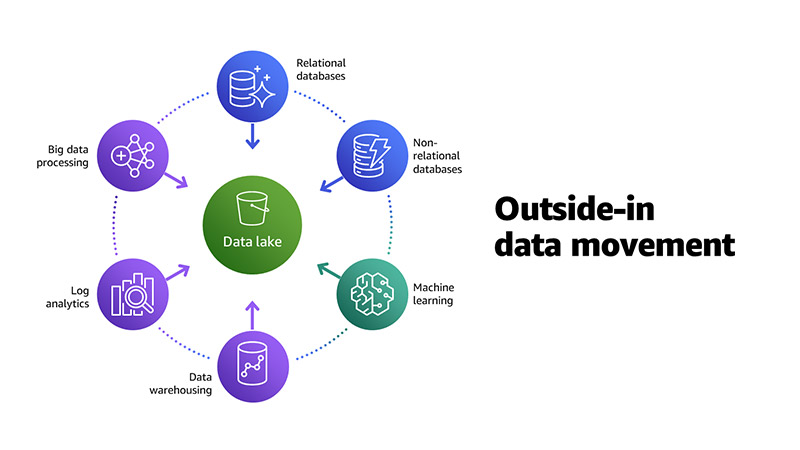
Figure 1: Big data architecture proposal
In the era of Big Data, a robust architecture is essential for managing vast data volumes efficiently. By leveraging data lakes and integrating diverse tools and technologies, we can transform raw data into actionable insights, ensuring scalability, flexibility, and governance at every step.

Pedro Bonillo
ML and Big Data Consultant
The proposed Data Architecture has the Data Lake as an integrating component through the AWS S3 and Lake Formation tools.
In such a way that all the data of the related Databases (AWS RDS); NoSql Databases (AWS Dynamo, Documentdb); Machine learning algorithms (AWS sagemaker); Data Warehouse fact and dimension tables (AWS redshift); transaction log files processed by microservices (AWS Kinesis Data Stream, Kinesis Firehose, and Kinesis Data Analytics); and the data from all aggregations, calculations, rules (AWS Glue and EMR) interacts with the Data Lake. (see, Figure 1)
The data lake is a single site where all structured (rows and columns), semi-structured (xml, json) and unstructured (images) data are stored.
The data lake stores the data in key value format (parquet) and compressed (through the gz and snappy algorithms), in such a way as to take advantage of the use of distributed computing frameworks for the calculation of aggregations and the presentation of data in the visualization analytical tools.
The data lake provides the possibility of having three data zones:
Raw data: Or the raw layer is the data as it comes from the origins.
Curated data: Or trusted data Contains the data with aggregations, transformations, data anonymization (pii), data hashing (pci).
Curated data: Or trusted data Contains the data with aggregations, transformations, data anonymization (pii), data hashing (pci).
Accessible data: The analytic layer or refined data or presentation data allows visualization tools and business units to access business objects: people, accounts, transactions, etc.; without having to worry about understanding tables and databases; thus uniting various data models based on rules to present reliable and democratized data to the business.
Inside-out data transfer: A subset of the data in the data lake is sometimes moved to a data warehouse, such as an RDS to store the data that feeds a visualization tool as superset, to support specialized analytics, such as analytics search, knowledge graph creation, or both.
Outside-in data transfer: Most companies use AWS RDS as the data stores for their microservices, and then move that data into the data lake. For example, to maintain a customer account statement, customer data, session history, and transaction tables are stored in AWS RDS, DynamoDB, and DocumentDB. This data is then exported to the data lake through AWS Glue and AWS EMR for further analysis, which improves the user experience of customer accounts.
Around the perimeter: In addition to the two patterns above, there are scenarios where data moves from one specialized data store to another. For example, data warehouse fact tables and dimensions in AWS Redshift can send data to the data lake or read data from the data lake.
Scalability: A data lake must be able to easily scale to petabytes and exabytes as data grows; use a persistent and scalable data store that allows the best performance at the lowest cost, with multiple ways to transfer the data.
Data diversity: Applications generate data in many formats. A data lake must support various types of data: structured, semi-structured, and unstructured.
Schema management: The choice of storage structure, schema, ingestion frequency, and data quality should be left to the data producer. A data lake must be able to accommodate changes to the structure of incoming data, something which is known as schema evolution. In addition, schema management helps ensure data quality by preventing writes that do not match the data.
Metadata management: Data must be self-discoverable with the ability to trace lineage as it flows through the different tiers (raw, curated, analytic) within the data lake. The AWS Glue data catalog is used, which captures the metadata and provides a query interface for all data assets.
Unified governance: The data lake design should have a strong mechanism for centralized authorization and auditing of data. Configuring access policies across the data lake and across all data stores can be extremely complex and error-prone. Having a centralized way to define policies and enforce them is critical to a data architecture.
Transactional semantics: In a data lake, data is often ingested almost continuously from multiple sources and queried simultaneously by multiple analytic engines. Having atomic, consistent, isolated, durable (ACID) transactions is critical to maintaining data consistency.
The proposed big data architecture is based on the reference model powered by AWS (see Figure 2). In this reference model, the following layers are presented from bottom to top.
DATA SOURCES: including software as a cloud computing service (SaaS), Online Transaction Processing databases, Enterprise Resource Planning databases, Customer Relation Management databases, the databases of each line of, shared files, mobile devices, web pages, sensors and social networks.
INGESTION LAYER: In this layer AWS suggests the use of DMS (Database Migration Services) that allows an initial loading of the data and marking a point of change (change data capture CDC) and keeping the extractions updated from this point, AWS DMS can send the data to AWS Kinesis for writing to the S3 distributed file system through AWS Kinesis Firehose, or stream it for further processing to AWS Kinesis Data Streams. Flow control of ingest processes is orchestrated through Amazon AppFlow and kept up-to-date using AWS DataSync.
STORE LAYER (Lake House Storage): This is the layer where the data lake is made up of different buckets of S3 (AWS distributed file system), these buckets can be in different accounts and in different regions, the important thing is that AWS proposes to classify data that is written to buckets into:
- Landing Zone: it is the zone in which the clean, anonymized, hashed data is found, and structured in a data model so that it can be interpreted by a business person and not a technical person and this data can come from different user AWS accounts.
- Raw Zone: in this zone the data is placed just as it comes from the different sources, without any treatment. The data in this zone is normally found in a secure environment.
- Trusted Zone: it is the zone where transformations are made to the data, for the necessary aggregations in the different analytical engines and for their subsequent security treatment.
- Curated Zone: in this zone all the mechanisms to comply with PII (personally identifiable information) and with the Payment Card Industry Data Security Standard are applied.
CATALOG MANAGEMENT LAYER (Lake House Catalog): The catalog of all the data that is in the data lake is managed through AWS Glue, with its schemas and the different versions of each data structure and with AWS Lake Formation data access permissions are managed, by schema, tables and even columns according to the roles defined in AWS IAM.
PROCESSING LAYER: This layer is divided into three sublayers:
- Datawarehouse (SQL-based ETL): sublayer where the fact tables (facts) and the dimensions (dim) that are updated through queries made on the different databases and even on the data lake are stored, this layer it is implemented using Amazon Redshift and is the source for the analytics engines (superset, Amazon QuickSight, tableau, power bi, etc).
- Big Data Processing: in this sublayer all the aggregation operations are carried out through the implementation of the mapping algorithm and reduction of the Apache Spark distributed computing framework, the use of servers that can be turned on and off for each calculation is called AWS Elastic Map Reduce (Amazon EMR) and the particular way to use Apache Spark with specific benefits for the AWS platform is called AWS Glue, in Glue workflows are declared that invoke jobs that contain the programs in python or python for apache spark (pyspark) that perform distributed computing and crawlers that read the data in one or several directories and automatically detect the structure and type of data and generate tables in the glue catalog, even recognizing partitions by year month day hour ( format that AWS Kinesis Firehose uses by default to write data to S3).
- Near to Real Time ETL: Through the implementation of Apache Spark Streaming and Kinesis Datastream, the data can be read from the source in near real time and can be processed in memory or written to S3, if the processing is done in memory AWS Kinesis Data Analytics can be performed to perform summarization, aggregation and send the data, for example, to the feature store that feeds the machine learning models.
CONSUMPTION LAYER: In this layer, Amazon Athena is used as a tool to perform SQL queries against the Glue catalog tables that are connected to the data lake and other data sources, Athena allows to establish workgroups that have quotas for perform queries that are executed using distributed computing on S3, Amazon Redshift can also be used to query the Datawarehouse tables, Amazon QuickSight to perform analytical reports and Amazon Sagemaker to perform machine learning models.
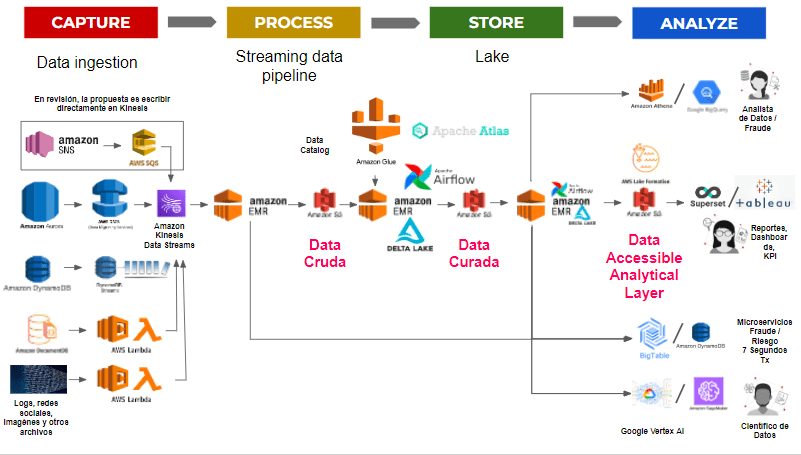
Figure 3: Proposed big data architecture with corresponding products
Are you busy reading out IT fires instead of focusing on your core business

The makers of AI have announced the company will be dedicating 20% of its compute processing power over the next four years

Discover how a 12-week sprint cycle can transform your data challenges into actionable insights, driving growth and innovation in your organization.

Discover the revolutionary Data Lakehouse architecture that combines the best of data warehouses and data lakes. Learn how this unified approach eliminates traditional data management challenges, supports AI integration, and transforms your analytics strategy.
Field Experience
Done Around World
Client Satisfaction
Established On
Response Time
+1 617 1286 4880
info@innovant.us
410 University Ave Westwood, MA 02090-2311
