Blog
The Key to Successfull Big Data: Agile Methodology in Four Sprints
By Pedro Bonillo, PhD, Machine Learning and Big Data Consultant.

By Pedro Bonillo, PhD, Machine Learning and Big Data Consultant.
A common mistake in the area of Software Development is to think that the big data methodology gets in the way, that it does not work, that it is a way of hindering, and since life is chaos, it is best to make the software without at least one plan and thus the projects are done with the idea of “When the time comes, we’ll see”. The truth is that no quality software product can ignore the process with which it is made and the product obtained.
Although agile methodologies are in fashion, they are nothing more than a response to the speed with which the market requires software to go into production. But it is important to be able to distinguish between tools, techniques, methods and methodologies.
A tool is something that is used in a workplace, for example Apache Hadoop. The technique is the efficient or effective way to use the tool, for example, using Apache Hadoop, with columnar format and writing the compressed files with Snappy. A Method is a path, a way to get from one point to another, for example, Map Reduce with Yarn or Spark on top of Apache Hadoop. A methodology is a set of methods on which it has been reflected after its application and that, when put into practice under the same premises, similar results are obtained.
In Big Data, many have tried to use orthodox methodologies, for example, now everything is Big Data or Big Data does not work for me. The reality is that the big data methodology must be agile and must start from the selection of a use case that solves a problem that cannot be solved with current tools, techniques, methods and methodologies.
In this way, the proposed Big Data methodology for projects is an adaptation of Scrum (agile and flexible methodology to manage software development), with 4 Sprints; the first two of 2 weeks; the third of 4 weeks; and the last of 6 weeks; for a total of 12 weeks; with daily reviews. (see, Figure 1).
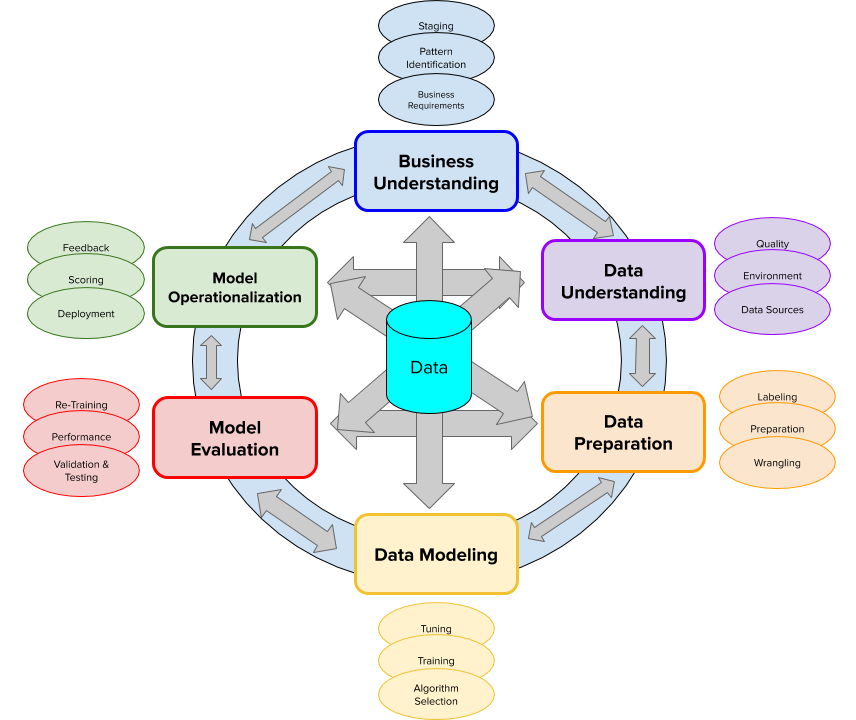
Figure 1: Methodology of Big Data projects
Quality software development requires more than just speed; it demands a structured approach. In Big Data, adopting an agile methodology tailored to unique challenges allows us to innovate effectively and solve complex problems that traditional methods can't address.

Pedro Bonillo
PhD, ML and Big Data Consultant
Customer experience has become a key differentiator in today's competitive landscape. IT services enable businesses to personalize customer interactions, provide efficient support through various channels, and offer seamless online experiences.
IT services facilitate data collection, storage, analysis, and visualization, turning raw information into actionable intelligence. By harnessing the power of data analytics, businesses can identify trends, customer preferences, and areas for improvement, leading to more effective strategies and increased profitability. Disruptions, such as natural disasters or system failures, can severely impact a business's operations. IT services include robust disaster recovery and backup solutions, ensuring that critical data is protected and can be swiftly recovered in case of any unforeseen events. This level of preparedness helps maintain business continuity and minimizes downtime,
Whether it's through chatbots, mobile apps, or responsive websites, IT services empower businesses to exceed customer expectations and build lasting relationships. Data is a goldmine of valuable insights that can help businesses make informed decisions.
In the first sprint, which we will call Ingredients Search, the possible use cases that we seek to improve through Big Data Management will be identified. This Sprint has a duration of 2 weeks. The selection criteria of the use case are at least three: volume (more than a million records), variability (many columns and some with null or nan), speed (perform queries that traditional relational database systems do not respond or take more than 5 minutes to respond).
In the second sprint (Prepare Food), it is necessary to identify in each of the use cases described in the previous sprint, which are the variables that we want to calculate (key performance indicator) or predict (Distillation Tier) in each case. This Sprint has a duration of 2 weeks.
In the third sprint (Food plating and Presentation), it is about selecting the most relevant use case for the organization, or what we will call the Golden Goal. A use case that could not be solved with traditional relational database systems or with available business intelligence tools and that can be addressed quickly, with less cost and with less effort using Big Data.
For this selected use case, it will be necessary to obtain the support of Senior Management, which implies evangelizing them based on the New Architecture and the Management of Large Volumes of Data. In addition, it is necessary to obtain the investment and expense budget to be able to execute the next Sprint, and thus be able to develop the use case, with the necessary Big Data components.
The word necessary is highlighted, since it is a common mistake to try to implement all the components of the Big Data Architecture for this use case. This sprint (the third) has a duration of 4 weeks.
The last sprint (Delivery Food), is divided into 3 stages:
PACKAGING:
In this stage the components of the Proposed Big Data Architecture for the selected use case are installed and configured. The extraction, transformation and loading of the data is carried out (according to the types of Information Acquisition defined: Real-time ingestion, Micro batch ingestion, Batch ingestion); their storage and use. Opportunities for improvement must be identified, regarding the increase on sales or optimizing processes. This stage lasts 4 weeks.
PROOF OF DELIVERY:
This second stage consists of verifying that the specifications of the use case were met, in order to correct assumptions in the strategy and be able to refine the Return on Investment. It lasts one week. Between this stage and the next, it is customary to adjust the learnings and select another use case to replicate these learnings in a new cycle of the methodology (sprint 5, Figure 1)
DISPOSABLE SERVICEWARE WASTE:
Finally it is necessary to measure the results and get rid of the waste, in such a way to document everything that worked and remove all the waste of what did not work or could not be applied. This stage lasts 1 week.
This methodology promotes the adaptation of the organization in an evolutionary and incremental way through the use of agile methods. This is why iteration through a phase of selecting a next use case is suggested.
Through this methodology we have been able to implement successful use cases in International Banks, Payment Processors for Uber and Google and financial fintech. Thus demonstrating that a period of twelve weeks or three months is enough to implement a successful Big Data use case, just to exemplify the AWS team implements its famous Data Lab using a methodology very similar to the one described above.
Are you busy reading out IT fires instead of focusing on your core business

Learn how to leverage AWS tools for seamless data integration, real-time analytics, and scalable storage solutions that transform your data into actionable insights.

Discover the revolutionary Data Lakehouse architecture that combines the best of data warehouses and data lakes. Learn how this unified approach eliminates traditional data management challenges, supports AI integration, and transforms your analytics strategy.

Learn how these cutting-edge approaches revolutionize big data strategies, empowering your organization with enhanced scalability, integration, and data-driven decision-making.
Field Experience
Done Around World
Client Satisfaction
Established On
Response Time
+1 617 1286 4880
info@innovant.us
410 University Ave Westwood, MA 02090-2311
